publications
publications on journals and conferences
2026
-
 Cross-View Yaw Estimation in Location Uncertainty with Line-Aligning Yaw ScoringTaeho Kang, Nairan Zhang, Yelin Kim, and 2 more authorsIn Computer Vision - ECCV 2026 - 19th European Conference, Malmö, Sweden, September 8-12, 2026, Proceedings, Sep 2026
Cross-View Yaw Estimation in Location Uncertainty with Line-Aligning Yaw ScoringTaeho Kang, Nairan Zhang, Yelin Kim, and 2 more authorsIn Computer Vision - ECCV 2026 - 19th European Conference, Malmö, Sweden, September 8-12, 2026, Proceedings, Sep 2026Accurate yaw estimation is a bottleneck in cross-view localization between ground view and Bird’s Eye View (BEV). Existing methods couple yaw with translation and rely on height or projection assumptions that degrade under large yaw ambiguity. We disentangle yaw from location accuracy and introduce LAYS, a radially invariant line-consensus voting method. By exploiting the radial invariance of our formulation, we achieve sub-degree yaw precision via 3D voting over all candidate poses, while eliminating the need for accurate location. Our key observation is that a ground-image column matched to BEV pixels induces the same yaw across all camera positions along the radial direction of the pixels. LAYS matches BEV pixels to ground columns using feature similarity and accumulates the induced yaw votes into discrete 3D bins, where correct correspondences along the radial line concentrate into a sharp peak for the correct yaw. Experiments on Mapillary, Ford, KITTI, and VIGOR show significant gains under unknown yaw, particularly for normal FoV with unknown yaw (+28 45\%p), and using LAYS as a yaw prior improves downstream 3-DoF localization.
@inproceedings{kang2026lays, author = {Kang, Taeho and Zhang, Nairan and Kim, Yelin and Shi, Yujiao and Lee, Youngki}, title = {Cross-View Yaw Estimation in Location Uncertainty with Line-Aligning Yaw Scoring}, booktitle = {Computer Vision - {ECCV} 2026 - 19th European Conference, Malm{\"{o}}, Sweden, September 8-12, 2026, Proceedings}, year = {2026}, month = sep, publisher = {Springer}, series = {Lecture Notes in Computer Science}, keywords = {cross-view localization, aerial view, 3D vision}, }

2025
-
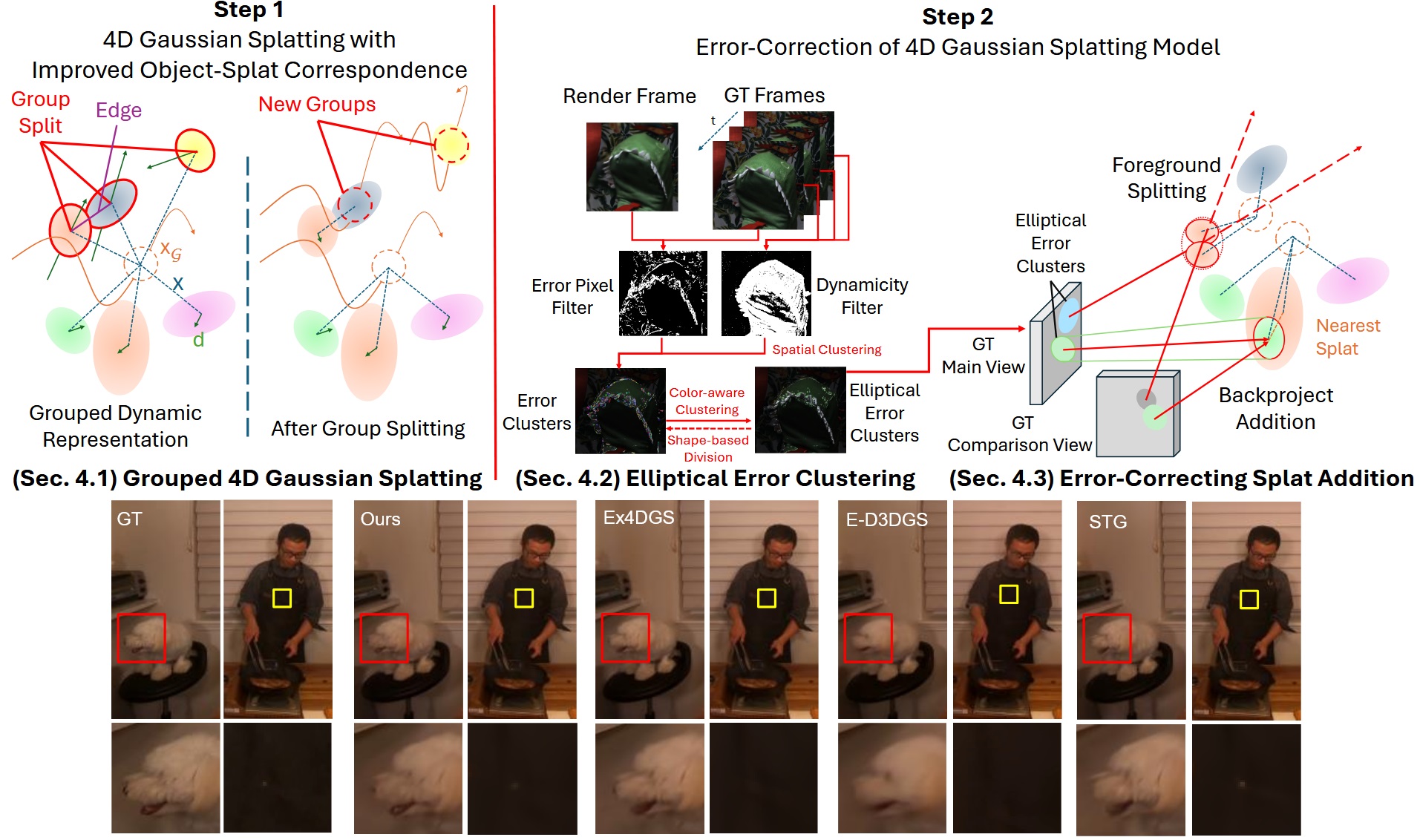 Clustered Error Correction with Grouped 4D Gaussian SplattingTaeho Kang, Jaeyeon Park, Kyungjin Lee, and 1 more authorIn SIGGRAPH Asia 2025 Conference Papers, Dec 2025
Clustered Error Correction with Grouped 4D Gaussian SplattingTaeho Kang, Jaeyeon Park, Kyungjin Lee, and 1 more authorIn SIGGRAPH Asia 2025 Conference Papers, Dec 2025@inproceedings{kang2025cem4dgs, title = {Clustered Error Correction with Grouped 4D Gaussian Splatting}, author = {Kang, Taeho and Park, Jaeyeon and Lee, Kyungjin and Lee, Youngki}, booktitle = {SIGGRAPH Asia 2025 Conference Papers}, month = dec, year = {2025}, pages = {1--12}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, doi = {10.1145/3757377.3763858}, url = {https://doi.org/10.1145/3757377.3763858}, series = {SA '25}, }

2024
-
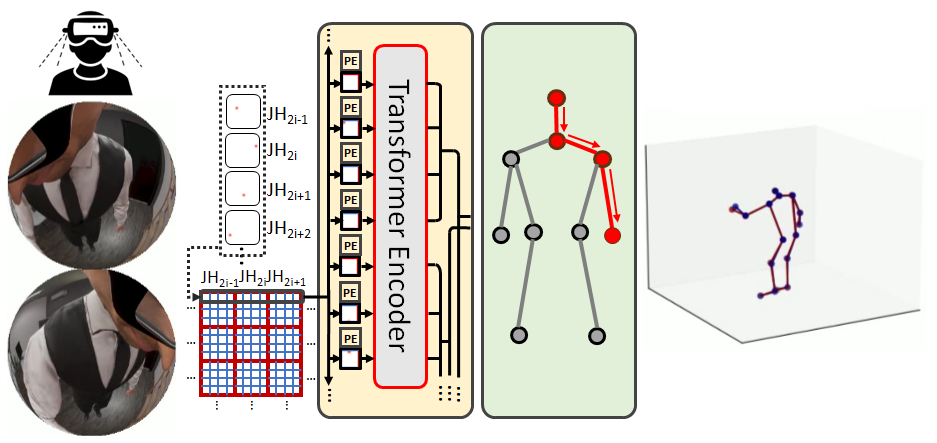 Attention-Propagation Network for Egocentric Heatmap to 3D Pose LiftingTaeho Kang, and Youngki LeeIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2024, Highlight324/11532 (2.8%)
Attention-Propagation Network for Egocentric Heatmap to 3D Pose LiftingTaeho Kang, and Youngki LeeIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2024, Highlight324/11532 (2.8%)@inproceedings{kang2024egotap, author = {Kang, Taeho and Lee, Youngki}, title = {Attention-Propagation Network for Egocentric Heatmap to 3D Pose Lifting}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, year = {2024}, pages = {842--851}, doi = {10.1109/CVPR52733.2024.00086}, }

2023
-
 Ego3DPose: Capturing 3D Cues from Binocular Egocentric ViewsTaeho Kang, Kyungjin Lee, Jinrui Zhang, and 1 more authorIn SIGGRAPH Asia 2023 Conference Papers, Dec 2023
Ego3DPose: Capturing 3D Cues from Binocular Egocentric ViewsTaeho Kang, Kyungjin Lee, Jinrui Zhang, and 1 more authorIn SIGGRAPH Asia 2023 Conference Papers, Dec 2023We present Ego3DPose, a highly accurate binocular egocentric 3D pose reconstruction system. The binocular egocentric setup offers practicality and usefulness in various applications, however, it remains largely under-explored. It has been suffering from low pose estimation accuracy due to viewing distortion, severe self-occlusion, and limited field-of-view of the joints in egocentric 2D images. Here, we notice that two important 3D cues, stereo correspondences, and perspective, contained in the egocentric binocular input are neglected. Current methods heavily rely on 2D image features, implicitly learning 3D information, which introduces biases towards commonly observed motions and leads to low overall accuracy. We observe that they not only fail in challenging occlusion cases but also in estimating visible joint positions. To address these challenges, we propose two novel approaches. First, we design a two-path network architecture with a path that estimates pose per limb independently with its binocular heatmaps. Without full-body information provided, it alleviates bias toward trained full-body distribution. Second, we leverage the egocentric view of body limbs, which exhibits strong perspective variance (e.g., a significantly large-size hand when it is close to the camera). We propose a new perspective-aware representation using trigonometry, enabling the network to estimate the 3D orientation of limbs. Finally, we develop an end-to-end pose reconstruction network that synergizes both techniques. Our comprehensive evaluations demonstrate that Ego3DPose outperforms state-of-the-art models by a pose estimation error (i.e., MPJPE) reduction of 23.1% in the UnrealEgo dataset. Our qualitative results highlight the superiority of our approach across a range of scenarios and challenges.
@inproceedings{10.1145/3610548.3618147, author = {Kang, Taeho and Lee, Kyungjin and Zhang, Jinrui and Lee, Youngki}, title = {Ego3DPose: Capturing 3D Cues from Binocular Egocentric Views}, year = {2023}, month = dec, isbn = {9798400703157}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3610548.3618147}, doi = {10.1145/3610548.3618147}, booktitle = {SIGGRAPH Asia 2023 Conference Papers}, articleno = {82}, numpages = {10}, keywords = {Egocentric, Stereo vision, 3D Human Pose Estimation, Heatmap}, location = {, Sydney, NSW, Australia, }, series = {SA '23}, } -
 SAME: Skeleton-Agnostic Motion Embedding for Character AnimationSunmin Lee, Taeho Kang, Jungnam Park, and 2 more authorsIn SIGGRAPH Asia 2023 Conference Papers, Dec 2023
SAME: Skeleton-Agnostic Motion Embedding for Character AnimationSunmin Lee, Taeho Kang, Jungnam Park, and 2 more authorsIn SIGGRAPH Asia 2023 Conference Papers, Dec 2023Learning deep neural networks on human motion data has become common in computer graphics research, but the heterogeneity of available datasets poses challenges for training large-scale networks. This paper presents a framework that allows us to solve various animation tasks in a skeleton-agnostic manner. The core of our framework is to learn an embedding space to disentangle skeleton-related information from input motion while preserving semantics, which we call Skeleton-Agnostic Motion Embedding (SAME). To efficiently learn the embedding space, we develop a novel autoencoder with graph convolution networks and provide new formulations of various animation tasks operating in the SAME space. We showcase various examples, including retargeting, reconstruction, and interactive character control, and conduct an ablation study to validate design choices made during development.
@inproceedings{10.1145/3610548.3618206, author = {Lee, Sunmin and Kang, Taeho and Park, Jungnam and Lee, Jehee and Won, Jungdam}, title = {SAME: Skeleton-Agnostic Motion Embedding for Character Animation}, year = {2023}, month = dec, isbn = {9798400703157}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3610548.3618206}, doi = {10.1145/3610548.3618206}, booktitle = {SIGGRAPH Asia 2023 Conference Papers}, articleno = {45}, numpages = {11}, keywords = {Motion Retargeting, Motion Embedding, Graph Neural Networks, Character Animations}, location = {, Sydney, NSW, Australia, }, series = {SA '23}, }

